Материалы по тегу: sambanova systems
|
09.07.2026 [00:56], Владимир Мироненко
SambaNova завершила первый этап раунда финансирования на $1 млрд с оценкой в $11 млрдРазработчик ИИ-ускорителей SambaNova объявил о завершении первого этапа раунда финансирования серии F, в рамках которого привлекла $1 млрд с оценкой её рыночной стоимости в $11 млрд. Раунд финансирования возглавила General Atlantic, при этом значительные инвестиции поступили от Seligman Ventures, T. Rowe Price Associates и Capital Group. Предыдущий раунд серии E с привлечением $350 млн инвестиций SambaNova провела в феврале этого года, вскоре после неудавшейся сделки с Intel. В число новых и существующих инвесторов входят A&E Investment, Assam Ventures, Battery Ventures, фонды и счета под управлением BlackRock, Cambium Capital, Intel Capital, Kabila Capital, QFO Capital, Qatar Investment Authority (QIA), Vista Equity Partners и Volantis. Родриго Лян (Rodrigo Liang, на фото), генеральный директор и соучредитель SambaNova, сообщил TechCrunch, что в ближайшие несколько недель присоединятся ещё несколько инвесторов, и, вероятно, завершится второй этап раунда финансирования. 
Источник изображения: SambaNova Привлечённые средства компания направит на расширение мощностей, ускорение инноваций в продуктах и масштабирование развёртывания. SambaNova сообщила, что будет и дальше развивать клиентские программы и продолжать инвестировать в чипы, системы, ПО и полнофункциональную ИИ-инфраструктуру. Также SambaNova объявила, что JPMorgan Chase выбрала SN40 и SN50 для ИИ-инференса в локальной среде. «Мы рады развернуть архитектуру RDU от SambaNova и с нетерпением ждем возможности протестировать её скорость и безопасность для локального выполнения задач в наших требовательных корпоративных рабочих ИИ-нагрузках», — сообщили в JPMorgan Chase.
02.06.2026 [17:57], Владимир Мироненко
Intel с партнёрами разработает эталонный дизайн ИИ-стоек с чипами Xeon для ODM- и OEM-производителей
clearwater forest
foxconn
granite rapids
hardware
intel
nvidia
odm
oem
sambanova systems
xeon
ии
инференс
стойка
Intel совместно с SambaNova и Foxconn объявила о намерении создать референс-дизайн стоечной ИИ-инфраструктуры на базе процессоров Intel Xeon для ЦОД, гиперскейлеров и центров интеллектуального управления. Как сообщает The Register, подход основан на ранее разработанной Intel совместно с SambaNova концепции дезагрегированного ИИ. Архитектура распределяет ресурсоёмкие операции предварительного заполнения между ускорителями NVIDIA, используя чипы SambaNova для ресурсоёмких операций декодирования, что позволяет увеличить выход токенов для каждого пользователя в 2–3 раза. Генеральный директор Intel Лип-Бу Тан (Lip-Bu Tan) представил два примера таких проектов. Один предназначен для агентных нагрузок, чувствительных к задержкам, а другой — для обеспечения максимальной плотности вычислений. Обе конфигурации поддерживают до 128 процессоров Intel: либо 128-ядерных Granite Rapids-AP, либо 288-ядерных Clearwater Forest, что в сумме составляет от 16 384 P-ядер до 36 864 E-ядер, а также до 384 Тбайт DDR5 при энергопотреблении 100 кВт. Тан сообщил, что системы на основе этого референс-дизайна будут широко доступны у ODM- и OEM-партнёров компании. В рамках сотрудничества Foxconn предоставит возможности системной интеграции для новой стоечной ИИ-инфраструктуры. Компания также планирует выпускать вариант стоечной инфраструктуры с высокой плотностью процессоров для рабочих нагрузок, не требующих дополнительного ускорения, включая оптимизированные по стоимости задачи инференса, обработку данных и гибридный ИИ. Intel объявила, что облачный провайдер Vector Core Compute, созданный Vista Equity Partners и Cambium Capital, станет одним из первых, кто развернёт эту платформу, а Together.AI — её первым коммерческим клиентом. 
Источник изображения: Intel Также на выставке Computex 2026 компании Intel, SambaNova, Vista Equity Partners и Cambium Capital представили первую реальную демонстрацию дезагрегированной системы инференса, использующей процессоры Intel Xeon 6 для оркестрации, блоки RDU SambaNova SN40 для декодирования и NVIDIA Blackwell для предварительного заполнения, работающую в ЦОД Vector Core Compute в Лос-Анджелесе. Напомним, что ранее NVIDIA объявила о запуске аналогичной стоечной платформы, включающей 256 88-ядерных процессоров Vera, ускорители Rubin и LPU Groq 3. Arm также работает над парой референс-дизайнов стоечных систем для агентных рабочих нагрузок на основе своих новых процессоров Arm AGI: 36-кВт системой с воздушным охлаждением и 8160 ядрами, а также 200-кВт системой с жидкостным охлаждением и 45 696 ядрами.
09.04.2026 [14:00], Владимир Мироненко
SambaNova и Intel готовят гетерогенное решение для агентного ИИ — конкурента продуктам NVIDIASambaNova в рамках следующего этапа сотрудничества с Intel анонсировала гетерогенное аппаратное решение, которое объединяет GPU, процессоры Intel Xeon 6 и RDU SambaNova для инференса для «самых требовательных» приложений агентного ИИ. Новинка вместе с полным ИИ-стеком станет доступна во II половине 2026 года. Компании также планируют развернуть облачную ИИ-платформу. В данном решении GPU отвечают за высокопараллельную фазу предварительного заполнения, эффективно преобразуя длинные запросы в KV-кеши, а RDU SambaNova обеспечивают высокопроизводительное декодирование с низкой задержкой. Xeon функционируют как хост-процессор для управления системой, координации задач агентного ИИ, распределения рабочей нагрузки, обработку API и т.д. Xeon также отвечает за компиляцию и запуск кода, он же проверяет результаты. 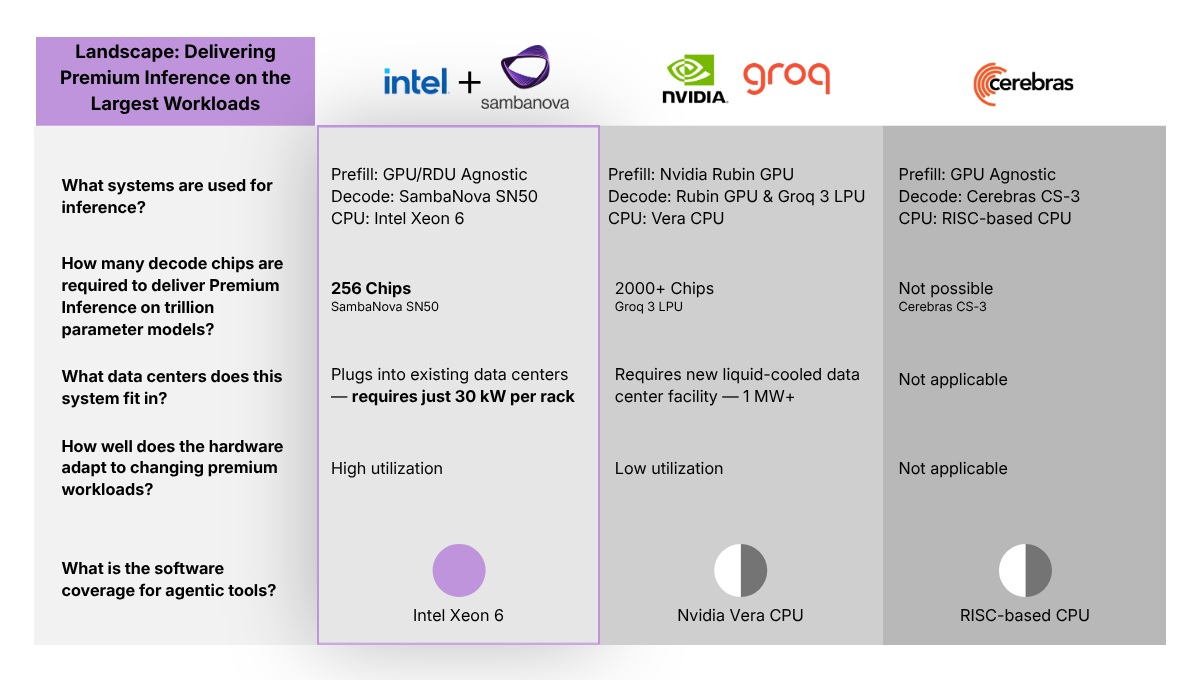
Источник изображений: Sambanova По результатам измерений SambaNova, Xeon 6 обеспечивает более чем на 50 % более быстрое время компиляции LLVM по сравнению с серверными процессорами на базе Arm и до 70 % более высокую производительность векторных баз данных по сравнению с доступными решениями на базе x86. Это ускоряет создание агентов, позволяя разработчикам быстрее переходить от идеи к реализации, говорят компании.  Как отметил ресурс Data Center Dynamics, это объявление было сделано спустя месяц после того, как SambaNova представила чип SN50 для рабочих нагрузок агентного ИИ, который, по утверждению компании, в пять раз быстрее конкурентов и втрое выгоднее с точки зрения TCO. Тогда же SambaNova также объявила о «многолетнем стратегическом сотрудничестве» с Intel для предоставления «высокопроизводительных и экономически эффективных решений для ИИ-инференса для компаний, занимающихся разработкой ИИ, поставщиков моделей, предприятий и государственных организаций по всему миру». Ранее Intel анонсировала похожую гибридную систему на базе собственных ускорителей Habana Gaudi3 и NVIDIA B200. Такого же подхода с распределением этапов инференса по разным чипам придерживается и NVIDIA в кластерах Vera Rubin, дополненных LPU Groq (вместо Rubin CPX). Основное различие между подходом Intel с SambaNova и подходом NVIDIA в том, что первый ориентируется на «более безопасный» вариант, поскольку не требует сложной базовой инфраструктуры для дезагрегированного инференса. Для заказчиков, ищущих более модульное решение стоечного масштаба, ориентированное на разделение «предварительное заполнение + декодирование», вариант Intel + SambaNova может быть более привлекательным.
03.04.2026 [18:36], Сергей Карасёв
Intel прикупит ещё чуть-чуть SambaNovaКорпорация Intel, по сообщению Reuters, намерена вложить дополнительно $15 млн в стартап SambaNova Systems, который занимается разработкой ИИ-ускорителей. В результате, доля Intel в структуре этой компании увеличится с 8,2 % до 9 %. Информация о том, что Intel присматривается к SambaNova, появилась в конце прошлого года. Причём тогда говорилось, что речь может идти о покупке стартапа, а стоимость сделки оценивалась в $1,6 млрд. Однако окончательно договориться сторонам так и не удалось, и SambaNova пришлось заняться поиском потенциальных инвесторов. В феврале стало известно, что компания ведёт переговоры о привлечении более $350 млн в рамках раунда финансировании серии E. 
Источник изображения: SambaNova Корпорация Intel, чей генеральный директор Лип-Бу Тан (Lip-Bu Tan) одновременно является председателем правления SambaNova, не так давно инвестировала в этот стартап $35 млн, нарастив долю с 6,8 % до 8,2 %. При этом стороны объявили о «стратегическом сотрудничестве». Теперь Intel намерена предоставить SambaNova дополнительные средства. Как отмечает Reuters, корпорация Intel вкладывает средства и в другие компании, связанные с Таном: в их число входят EPIC Microsystems, 3D Glass Solutions и OPAQUE Systems. В частности, в январе Intel инвестировала $2,3 млн в стартап по разработке ИИ-решений OPAQUE Systems, получив в обмен 14 % долю в этой компании. Кроме того, Intel направила $3,4 млн в стартап EPIC Microsystems, который занимается созданием инновационных интегральных схем для управления питанием. А в 3D Glass Solutions в рамках двух раундов финансирования Intel вложила $8 млн.
24.02.2026 [23:00], Владимир Мироненко
SambaNova представила ИИ-ускоритель SN50 и объявила о расширении партнёрства с IntelSambaNova представила ИИ-ускорители пятого поколения SN50 на основе фирменных RDU (Reconfigurable Dataflow Unit), которые, по словам компании, «обеспечивает непревзойденное сочетание сверхнизкой задержки, высокой пропускной способности и энергоэффективной производительности для рабочих нагрузок ИИ-инференса, коренным образом меняя экономику генерации токенов». Кроме того, объявлено об инвестициях и сотрудничестве с Intel, которая передумала покупать SambaNova целиком. Как отметил The Register, новый чип представляет собой значительное улучшение по сравнению с SN40L 2023 года. По данным компании, SN50 обеспечивает в 2,5 раза более высокую производительность при 16-бит вычислениях (1,6 Пфлопс) и в 5 раз более высокую производительность в режиме FP8 (3,2 Пфлопс). В основе SN50 лежит архитектура потоковой обработки данных (SambaNova DataFlow). Как и в предшественнике, в SN50 используется трёхуровневая иерархия памяти, которая сочетает в себе DDR5, HBM и SRAM, что позволяет платформам на основе новинки поддерживать ИИ-модели с 10 трлн параметров и длиной контекста до 10 млн токенов. 
Источник изображений: SambaNova Каждый RDU оснащен 432 Мбайт SRAM, 64 Гбайт HBM2E с пропускной способностью 1,8 Тбайт/с и от 256 Гбайт до 2 Тбайт памяти DDR5. Доступность HBM2E и конфигурируемый объём DDR5 позволят повысить привлекательность и доступность SN50 на фоне дефицита памяти. Каждый ускоритель получил интерконнект со скоростью 2,2 Тбайт/с (в каждую сторону) для связи с другими чипами через коммутируемую фабрику. Как утверждает SambaNova, по сравнению с ускорителем NVIDIA B200, SN50 обеспечивает в 5 раз большую максимальную скорость генерации токенов на пользователя и более чем в 3 раза большую пропускную способность для агентного инференса, что было продемонстрировано на примере ряда моделей, таких как Meta✴ Llama 3.3 70B. Архитектура позволяет эффективно разгружать KV-кеш и переключаться между моделям в HBM и SRAM в режиме «горячей замены» за миллисекунды, что крайне важно для агентных рабочих нагрузок, часто переключающихся между несколькими ИИ-моделями.  Также в SN50 входные токены могут кешироваться в памяти, сокращая время предварительной обработки и время ожидания первого токена (TTFT) для запросов. Такое сочетание производительности, эффективности и масштабируемости обеспечивает преимущество в совокупной стоимости владения (TCO), по словам компании, не имеющее аналогов на рынке, для поставщиков сервисов инференса, использующих такие модели, как OpenAI GPT-OSS, с восьмикратной экономией по сравнению с NVIDIA B200. SN50 ориентирован и на такие приложения, как голосовые помощники на основе ИИ, требующие сверхнизкой задержки для работы в режиме реального времени. По заявлению компании, он сможет обеспечить работу тысяч одновременных сессий. Также была представлена 20-кВт система SambaRack SN50, которая объединяет 16 чипов SN50. SambaRack могут масштабироваться до кластера из 256 ускорителей с пропускной способностью интерконнекта в несколько Тбайт/с, что сокращает время обработки запросов и поддерживает большие размеры пакетов. В результате можно развёртывать модели с более высокой пропускной способностью и быстродействием. Поставки SN50 клиентам начнутся во II половине 2026 года.  Раннее SambaNova сообщила о привлечении более $350 млн в рамках переподписанного раунда финансирования серии E, возглавляемого частной инвестиционной компанией Vista Equity Partners при партнёрстве с Cambium Capital. В нём также приняло «активное участие» инвестиционное подразделение Intel — Intel Capital, сообщил SiliconANGLE. Также SambaNova заявила о сотрудничестве с Intel в разработке новых высокопроизводительных и экономически эффективных систем для выполнения ИИ-задач. Цель — предоставить предприятиям альтернативу GPU, которые сегодня используются в большинстве рабочих нагрузок. Intel инвестирует в стартап, чтобы ускорить развёртывание нового «облачного решения для ИИ» на базе существующей платформы SambaNova Cloud. Обновлённая платформа, оптимизированная для многомодальных LLM, получит процессоры Xeon, а также GPU, сетевые и иные решения Intel, в том числе в области СХД. Идёт ли речь о создании специализированных моделей Xeon, как это было в случае NVIDIA, не уточняется. В дальнейшем Intel и SambaNova планируют совместно продвигать и продавать новую платформу, используя существующие связи Intel с предприятиями и партнёрские каналы.  Партнёрство несёт выгоду обеим компаниям. SambaNova сможет воспользоваться глобальным охватом и производственной базой Intel для масштабирования своих ИИ-ускорителей, а Intel получит шанс наконец-то заявить о себе на ИИ-рынке. До сих пор Intel не могла конкурировать с NVIDIA и другими производителями чипов, такими как AMD, в ИИ-сфере. Чипы SN50 от SambaNova в сочетании с процессорами Intel Xeon потенциально могут изменить эту ситуацию. Стоит отметить, что у Intel, которая сама чувствует себя не лучшим образом, есть довольно крупная сделка с NVIDIA. Компания также предлагает собственные GPU для инференса, пусть и значительно более простые в сравнении с SN50, и даже странные гибриды из ускорителей Habana Gaudi 3 и NVIDIA B200. Наконец, имеется и сделка с AWS по выпуску кастомных Xeon 6 и неких ИИ-ускорителей. Что касается старых «коллег» SambaNova в деле борьбы с NVIDIA, то Groq в итоге была поглощена последней, а Cerebras, наконец, подписала заметную сделку с действительно крупным игроком на рынке ИИ — OpenAI.
09.02.2026 [09:10], Владимир Мироненко
Хоть инвестиций клок: SambaNova проведёт раунд на $350 млн при поддержке IntelСтартап в сфере разработки ИИ-чипов SambaNova Systems ведёт переговоры о привлечении более $350 млн в рамках раунда финансировании серии E, сообщило агентство Reuters. Раунд возглавляет частная инвестиционная компания Vista Equity Partners, которая до этого инвестировала исключительно в компании, занимающиеся корпоративным ПО. Компания, известная крупными сделками в сфере ПО, приобрела в 2022 году компанию облачных вычислений Citrix Systems и компанию-разработчика ПО Nexthink в 2025 году. Сообщается, что это изменение может быть вызвано масштабной распродажей акций компаний-разработчиков ПО на этой неделе. По данным источников Reuters, в раунде также примут участие венчурная компания Cambium Capital и Intel. В частности, Intel, как сообщается, планирует инвестировать около $100 млн с потенциальным обязательством направить $150 млн. Оценка рыночной стоимости, которую SambaNova может получить по итогам раунда, не уточняется. Источники предупредили, что привлечение средств продолжается, и окончательные условия раунда могут измениться. 
Источник изображения: SambaNova Источники сообщили, что SambaNova начала искать новое финансирование в прошлом месяце после того, как переговоры о её приобретении компанией Intel зашли в тупик. В декабре появилась информация о том, что Intel предложила за SambaNova $1,6 млрд, включая долг. Это примерно треть от суммы в $5 млрд, в которую оценивалась рыночная стоимость SambaNova после последнего раунда финансирования в 2021 году, возглавляемого фондом SoftBank Vision Fund 2. С момента основания в 2017 году SambaNova привлекла более $1 млрд инвестиций и переориентировалась на разработку решений в области ИИ и облачных сервисов. С тех пор компания столкнулась с трудностями и провела сокращения персонала в 2024 году. В прошлом месяце компания сообщила сотрудникам, что превысила целевой показатель продаж за 2025 финансовый год. Рост числа клиентов SambaNova может быть одной из причин, по которой компания привлекла интерес институциональных инвесторов и Intel, допускает ресурс SiliconANGLE. В июле прошлого года SambaNova представила услугу SambaManaged, которая сокращает время развёртывания ИИ-оборудования в типовом ЦОД до 90 дней. В течение следующих шести месяцев компания заключила контракты на поставку оборудования с четырьмя различными операторами ЦОД. В рамках одного из контрактов SambaNova будет поставлять чипы для суверенного облачного кампуса в Шотландии с запланированной мощностью более 2 ГВт. Флагманский продукт SambaNova — ИИ-ускоритель для инференса SN40L, содержащий 1040 ядер, изготовленных с использованием 5-нм техпроцесса TSMC, имеет производительность 638 Тфлопс в режиме BF16. Компания поставляет чипы в составе системы SambaStack с воздушным охлаждением, которая содержит 16 ускорителей SN40L, а также включает в себя сетевое оборудование и компоненты управления питанием. SambaStack позволяет запускать ИИ-модели с до 5 трлн параметров.
23.01.2026 [13:07], Руслан Авдеев
Застопорившаяся сделка с Intel заставила SambaNova искать $500 млн дополнительных инвестицийПоставщик ИИ-ускорителей SmabaNova рассчитывает привлечь до $500 млн в ходе раунда финансирования после того, как приостановились переговоры с Intel. Последняя рассматривала возможность покупки SambaNova, пишет Bloomberg. Ранее появилась информация, что компании вели расширенные дискуссии о возможном поглощении SambaNova, включая долг, компанией Intel за $1,6 млрд, но окончательное решение так и не было принято. Переговоры пока не принесли результатов, и поставщик ИИ-решений теперь ищет инвестиции из других источников — технологических компаний и производителей полупроводников. При этом глава Intel Лип-Бу Тан (Lip-Bu Tan) одновременно является председателем SambaNova. Первые слухи о том, что SambaNova рассматривает возможность продажи, появились в октябре 2025 года. По данным источников The Information, компания наняла инвестиционную структуру для того, чтобы та курировала потенциальную покупку. 
Источник изображения: SambaNova В 2021 году SambaNova оценивалась в $5 млрд, а всего с момента основания привлекла более $1,1 млрд от инвесторов, включая GV, Intel Capital, BlackRock и SoftBank Vision Fund. Однако BlackRock, владеющая акциями SambaNova, ранее снизила оценку до $2,4 млрд. Теперь же, по-видимому, даже оценка в $1,6 млрд не является корректной. Основанная в 2017 году SambaNova изначально ориентировалась на обучение ИИ-моделей, но затем переключилась на услуги облачного и локального инференса с использованием собственных ИИ-чипов SN40L, представленных в сентябре 2023 года.
10.12.2025 [20:02], Владимир Мироненко
Intel договорилась о покупке разработчика ИИ-ускорителей SambaNova за $1,6 млрд, но не окончательноРесурсу Wired стало известно о подписании Intel соглашения о покупке ИИ-стартапп SambaNova Systems. Финансовые условия соглашения, которое носит предварительный характер и не имеет обязательной силы, не разглашаются. Впервые о заинтересованности Intel в приобретении стартапа сообщил Bloomberg в конце октября. На тот момент переговоры находились на ранней стадии. Согласно данным ресурса, сумма предполагаемой сделки составляла менее $5 млрд. Что примечательно, генеральный директор Intel Лип-Бу Тан (Lip-Bu Tan) в настоящее время является исполнительным председателем и инвестором SambaNova Systems, сообщили источники The New York Times, знакомые с ситуацией. И он рассказывал о предложениях SambaNova на встречах как минимум с одним крупным клиентом Intel, компанией Dell. Intel Capital, которую сейчас выделяют в отдельную компанию, также инвестировала в SambaNova Systems. Ещё один инвестор SambaNova, японская SoftBank Group, также является крупным инвестором Intel. 
Источник изображения: SambaNova Systems SambaNova Systems была основана в 2017 году в Пало-Альто (Palo Alto, Калифорния, США) Кунле Олукотуном (Kunle Olukotun), Родриго Ляном (Rodrigo Liang) и Кристофером Ре (Christopher Ré). Олукотун и Ре — профессора Стэнфордского университета. Лян ранее был топ-менеджером в Oracle. По данным PitchBook, к началу 2025 года компания привлекла $1,14 млрд инвестиций. В частности, в 2020 году она получила $250 млн от BlackRock, Intel Capital, венчурной фирмы GV и других инвесторов, а её оценка выросла до $2,5 млрд. В 2021 году SambaNova была оценена в $5 млрд после раунда финансирования в размере $676 млрд, возглавляемого фондом SoftBank Vision Fund 2. С тех пор предполагаемая оценка стартапа снизилась. По данным The Information, BlackRock снизила стоимость своих акций SambaNova на 17 % за последний год. Это, вероятно, сделало компанию целью для Intel, наряду с тем фактом, что Intel отстаёт от остальной части индустрии чипов в производстве ИИ-чипов, отметил Wired. Разработки купленной когда-то Habana едва продаются, а после отказа от Ponte Vecchio, проблем с запуском Falcon Shores и неопределённостью относительно Jaguar Shores у Intel практически не осталось «больших» ускорителей. О сделке с Nervana в компании предпочитают не вспоминать. SambaNova разрабатывает ИИ-ускорители на основе реконфигурируемого блока обработки данных (Reconfigurable Dataflow Unit, RDU). 5-нм ускоритель SN40L, представленный более двух лет назад, имеет 1040 ядер RDU, обеспечивающих производительность до 653 Тфлопс в режиме BF16. Он оснащён 520 Мбайт SRAM, 64 Гбайт HBM3 с внешним DDR5-массивом объёмом 1,5 Тбайт для размещения LLM. Компания фактически отказалась от попыток конкурировать с NVIDIA в задачах обучения ИИ. Вслед за Groq она переключилась на инференс и поставку готовых ИИ-платформ вместо продажи ускорителей. UPD 13.12.2025: по данным Bloomberg, переговоры между компаниями значительно продвинулись — Intel готова приобрести SambaNova за $1,6 млрд с учётом долгов последней. Если сделка состоится, она станет первой крупной покупкой «синих» под руководством Лип-Бу Тана.
02.11.2025 [12:03], Сергей Карасёв
Intel интересуется покупкой разработчика ИИ-ускорителей SambaNova Systems, в которого инвестировал сам Лип-Бу ТанКорпорация Intel, по сообщению Bloomberg, ведёт предварительные переговоры о покупке стартапа SambaNova Systems, специализирующегося на разработке ИИ-ускорителей. Сделка теоретически позволит Intel укрепить конкурентное положение по отношению к NVIDIA. SambaNova основана в 2017 году профессорами Стэнфордского университета (Stanford University) в США. Компания занимается созданием ускорителей RDU (Reconfigurable Dataflow Unit) для работы с большими языковыми моделями (LLM) и инференса. С момента своего появления SambaNova привлекла более $1,1 млрд от GV, Intel Capital, BlackRock, SoftBank Vision Fund и др. В 2021 году стартап был оценён в $1,1 млрд. Однако в последнее время компания столкнулась со сложностями: ей не удалось провести очередной раунд финансирования, а рыночная стоимость пошла на спад. Весной нынешнего года SambaNova сократила численность персонала на 15 %, уволив 77 из 500 сотрудников. Тогда говорилось, что компания намерена переориентироваться на предоставление облачного ИИ-инференса. А недавно стало известно, что SambaNova изучает возможность продажи бизнеса. 
Источник изображения: SambaNova По сведения Bloomberg, к SambaNova присматривается Intel. Уточняется, что переговоры находятся на начальной стадии, поэтому сделка может не состояться. Кроме того, не исключатся вероятность появления другого покупателя. Представитель SambaNova, не вдаваясь в детали, заявил, что компания «ищет стратегические возможности, которые соответствуют её миссии и интересам акционеров». В Intel от комментариев отказались. Нужно отметить, что нынешний генеральный директор Intel Лип-Бу Тан (Lip-Bu Tan) одновременно является председателем правления SambaNova. Его венчурная компания Walden International была одним из первых инвесторов SambaNova, возглавив раунд финансирования Series A на сумму $56 млн в 2018 году. Таким образом, для Тана компания SambaNova — это хорошо знакомый бизнес. Для самой Intel попытки закрепиться на рынке «большого» ИИ оказались не слишком успешными. Приобретение Nervana (Lake Crest/Knights Crest) закончилось полным провалом, а создававшиеся в то же время собственные Xeon Phi компания в итоге забросила. Продажи ускорителей поглощённой когда-то Habana оставляют желать лучшего, так что сейчас компания, по-видимому, пытается хоть как-то сбыть их остатки. Собственные Ponte Vecchio (Intel Max) компания так же оставила без поддержки, Falcon Shores она решила никому не продавать, а будущее Jaguar Shores не известно.
28.10.2025 [15:02], Руслан Авдеев
SambaNova может быть выставлена на продажу — компании не удалось привлечь достаточно средствРазработчик ИИ-ускорителей SambaNova Systems изучает возможность продажи бизнеса. Компании не удалось вовремя завершить очередной рануд финансирования. По данным источников, знакомых с вопросом, она уже наняла инвестиционную компанию для контроля продажи, но переговоры продолжаются, т.ч. SambaNova всё ещё может передумать, сообщает The Information. Исполнительным председателем компании является Лип-Бу Тан (Lip-Bu Tan), нынешний глава Intel. В 2021 году капитализация компании оценивалась в $5 млрд. С момента основания SambaNova привлекла более $1,1 млрд, инвесторами выступили GV, Intel Capital, BlackRock и SoftBank Vision Fund. Издание говорит об отчёте Caplight, в котором указано, что BlackRock снизила оценочную стоимость своих акций в компании на 17 %, в результате чего общая оценка капитализации SambaNova упала до $2,4 млрд. SambaNova не прокомментировала возможную продажу, а её представитель заявил, что компания всегда оценивает стратегические возможности, поддерживающие её миссию, а также интересы владельцев. Основанная в 2017 году калифорнийская компания специализировалась на ИИ-ускорителях для обучения LLM, но в 2025 году сменила профиль на предоставление облачных ИИ-сервисов и инференс, повторив подход Groq. Последней, правда, повезло больше — она активно заключает сделки, получает инвестиции и создаёт ИИ ЦОД. У Cerebras дела идут ещё лучше, хотя и не идеально. Cerebras, Groq и SambaNova стали чуть ли не единственными компаниями, которые относительно успешно смогли конкурировать с NVIDIA и AMD на рынке «больших» ИИ-ускорителей. Последний продукт SambaNova — готовый ПАК SambaManaged на базе представленного два года назад ускорителям SN40L — популярности пока не снискал. 
Источник изображения: SambaNova Если SambaNova решится на продажу, она пополнит растущие ряды стартапов по выпуску ИИ-чипов, купленных за последние 12 месяцев. Так, Meta✴ объявила о покупке за неназванную сумму стартапа Rivos, занимающегося разработкой чипов на архитектуре RISC-V. Хотя сумма сделки неизвестна, ранее сообщалось, что стартап рассчитывал привлечь $500 млн с капитализацией $2 млрд. За полгода до этого южнокорейская FuriosaAI, тоже разрабатывающая ИИ-чипы, отклонила предложение Meta✴ о покупке за $800 млн. В этом году 2025 года SoftBank заявила о приобретении Ampere Computing за $6,5 млрд, а в прошлом году она приобрела разработчика ИИ-ускорителей Graphcore, у которого тоже были проблемы с финансами. Впрочем, бывают ситуации и похуже. Например, летом AMD купила команду разработчика ИИ-чипов Untether AI, но не саму компанию, которая тут же закрылась, оставив за бортом текущих клиентов стартапа. У Esperanto, создателя уникального тысячеядерного RISC-V-ускорителя, всех инженеров переманили крупные компании. Одним из возможных покупателей SambaNova называют Oracle, которая, по слухам, заинтересована именно в команде разработчиков, а не самих чипах. |
|

